



Data Cleaning
To identify patterns in art images, we need to first create a database of artworks with relevant fields to apply machine learning algorithms, such as K Nearest Neighbours (KNN). Finding the Hue, Saturation, Values, as discussed in a previous article, can aid in the creation of a useful database.
Data cleaning is a crucial step in any data analytics project. To analyse colours for our study, we need to first pre-process our data in a format that best suits our needs. For our study, we are mainly focusing on a data set available from the Art Institute of Chicago – as described in this Github.
This data set consists of a total of 122,435 artworks, with parameters of the artwork, such as artists, year, category, type of artwork etc codified in a JSON file. In the JSON file, it also consists of a link to the artwork, which is crucial for our project, as it allows us to download the related image for further processing for each of the image.
Data Cleaning Process

We follow a simple data-cleaning process to get useful information to further run our algorithms to extract colours and perform comparisons.
Extracting Information
First, we extract relevant information from both the API and the info dump from the Chicago data set. The following data table is what we have extracted from the JSON file and the rationale for why we chose to extract it for further analysis.
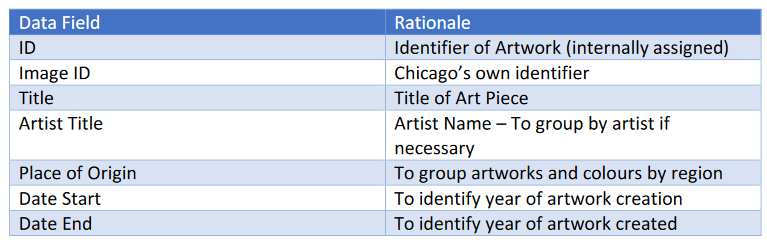
An important step that we took was to filter the dataset for paintings, watercolour, and drawings. The data set consists of other artworks such as sculptures, carvings etc., where the colours that we are extracting may not be accurate, simply because they are a different medium. As such, we filtered the data based on the above, which reduced the data set to 16,202 artworks that are relevant for our study.
Understanding the Data Set
After extracting the data, we first looked at the type of data that we have. To do this, we looked at the count of artworks by place of origin and by year to understand if there are certain biases in our data set.
By Place of Origin
The histogram below shows the number of artworks by country (for countries with more than 50 artworks). There is a strong weightage of artwork towards United States, probably because this is the data set from Art Institute of Chicago.

We see many artworks in 1600, 1700 and 1800. This could be due to poor data labelling because in those years, the data collection process of when exactly each artwork happened is not recorded accurately. This could lead to some wrong inferences in those years of artwork as there is a much larger data set in those years. These are the periods of Baroque (1600 – 1725), Rococo (1720 – 1760) and Neoclassicism (1770 – 1840) art movements.

To enrich our data, we will be looking at combining the data with WikiArt.-Kaggle.This data set can help us enrich the data.
Specifically, the WikiArt data set would have a more representative artworks outside of the United States that could help our study of colour be more diverse.
It is also a richer data set with 96,014 artworks that are largely relevant to paintings and easily accessible images via the Kaggle site. This gives us the confidence that the WikiArt dataset will be able to enrich our data study of colours throughout the years and regions. The same way of data cleaning and processing can be employed, and the challenge would be to map the data fields to the same way that the Chicago Art dataset is using for consistent results.
Processing the Images
We process the image using OpenCV firstly using K-means to extract the dominant colours and then extracting the Hue, Saturation and Value for further processing. Taking a sample of 5 images the time taken for extracting this value would take approximately 44.2 seconds.

Next Steps
We will continue to process the images in both the Chicago data set and enrich it with the WikiArt data set with our current algorithm. This will allow us to extract the dominant colours and find correlations between colours across regions and years.
More About the Authors
Melissa Connelly –
https://www.linkedin.com/in/melissanconnelly/
Si Hong Lu –
https://www.linkedin.com/in/sihong-lu/
Bryan Tan Wei Yoong –
https://www.linkedin.com/in/twyb